
Reading between the lines
- Originally authored ⎯ June 6, 2021
The value of a computer does not stem from its inherent capacity to do things well ⎯ it stems from an operator’s capacity to elucidate and structure what we want from the computer, it stems from a quiet conviction that this computer can do umpteen mathematical calculations faster than me, better, with more accuracy and speed I can only imagine of.
That very notion shows us what we can do with computers is often limited by the depths to which we can think creatively, transcribe these thoughts into coherent and articulated steps/instructions, and then share that work with others. Often, due to this, tools that leverage the power of collaborative creation hold immeasurable power to architect the way we communicate, articulate ideas, and translate that into knowledge forms understandable to completely different stakeholders ⎯ and this thesis seeks to explore newer paradigms of interacting with programs that leverage GPT-3’s articulate text generation capabilities to craft a semblance of human intuition for software, an experimental simulation that seeks to answer a fundamental question - “What if software could infer what the operator wants to do, and present to them the tools to get it done, without the operator’s explicit intervention?”
Function calling and JSON output were released with GPT-3.5 and above much later in mid-2023. Most of the approaches and monkey patches you’d find below are unnecessary in the face of recent updates to GPT.
Early tools
In the mid-1950s, computers were still room-sized execution machines to be fed on a singular diet of punch cards. Human operators broke down a problem into tasks and fed them into the machine in the precise way that the machines understood, and the computer would perform the desired operation.
Even later, with the advent of computers as personal terminals, the singular gateway to interface with the machine was still by typing specific commands in the terminal, that executed those commands to open up the vast underbellies of specific programs. The needle moved from punch cards and 0s and 1s to a layer above in abstractions. But the way we interface with machines is still far way off from how we interface with humans.
Alan Turing was once having arguments with his colleagues and critics over whether a machine could ever have human-level intelligence.
To prove his point, Turing proposed a game. In the game, an interrogator would ask questions to a human and a computer through a text-only chat interface. If the interrogator doesn't find any difference between both their responses and the computer can successfully project itself as a real human then it passes the test. Turing called it ⎯ the imitation game.
Thereafter, between 1964 and 1967, Joseph Weizenbaum developed an early natural language processing computer program called ELIZA. Created to explore communication between humans and machines, ELIZA simulated conversation by using a pattern matching and substitution methodology that gave users an illusion of understanding on the part of the program, but had no representation that could be considered “understanding” what was being said by either party. The ELIZA program itself was originally written in MAD-SLIP, the pattern matching directives that contained most of its language capability were provided in separate "scripts", represented in a lisp-like representation. The most famous script, DOCTOR, simulated a psychotherapist of the Rogerian school (in which the therapist often reflects back the patient's words to the patient) and used rules, dictated in the script, to respond with non-directional questions to user inputs.
But methods notwithstanding, ELIZA was one of the first computer programs (early chatbot) that could attempt Turing’s
imitation game.

While ELIZA was eligible to appear for Turing’s imitation game (later formalized in computational sciences as the Turing Test), it functioned with a very basic technology underneath.
Essentially, you type a sentence, the program breaks it down and looks for keywords in that sentence ⎯ and then it passes the keywords through pre-programmed modifiers and response templates, resulting in a human-like response.
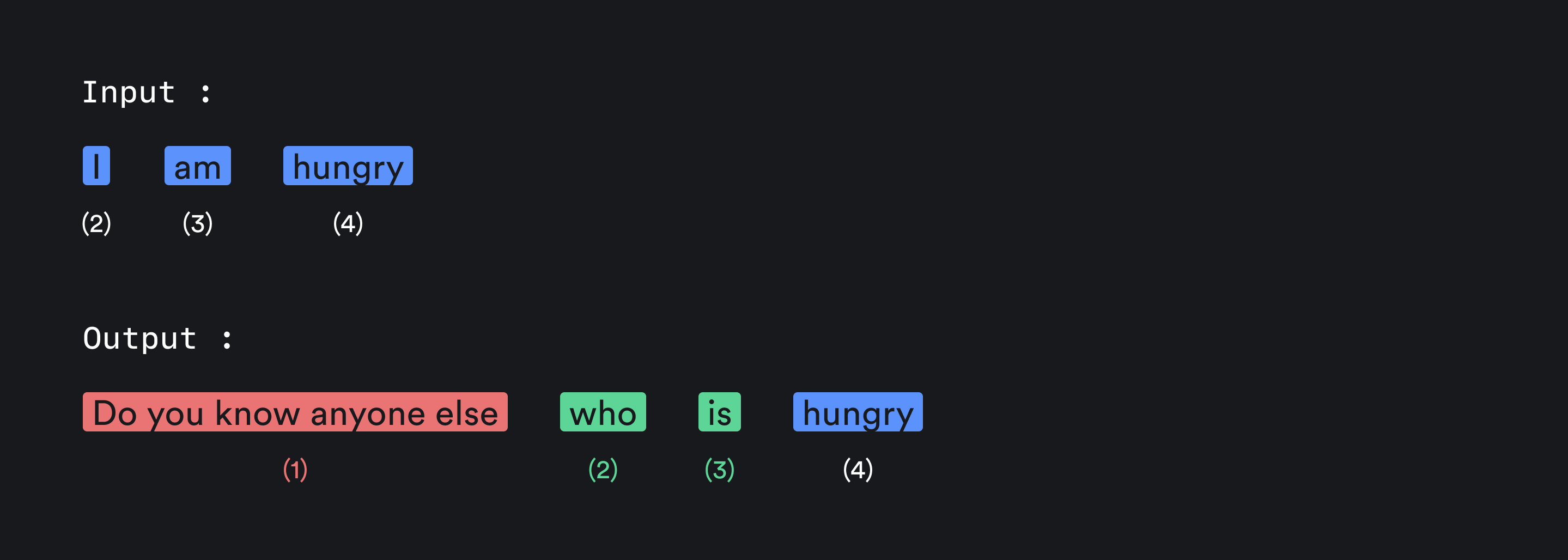
Sometimes, when it does not understand what the user is saying, it simply repeats their words back to them.
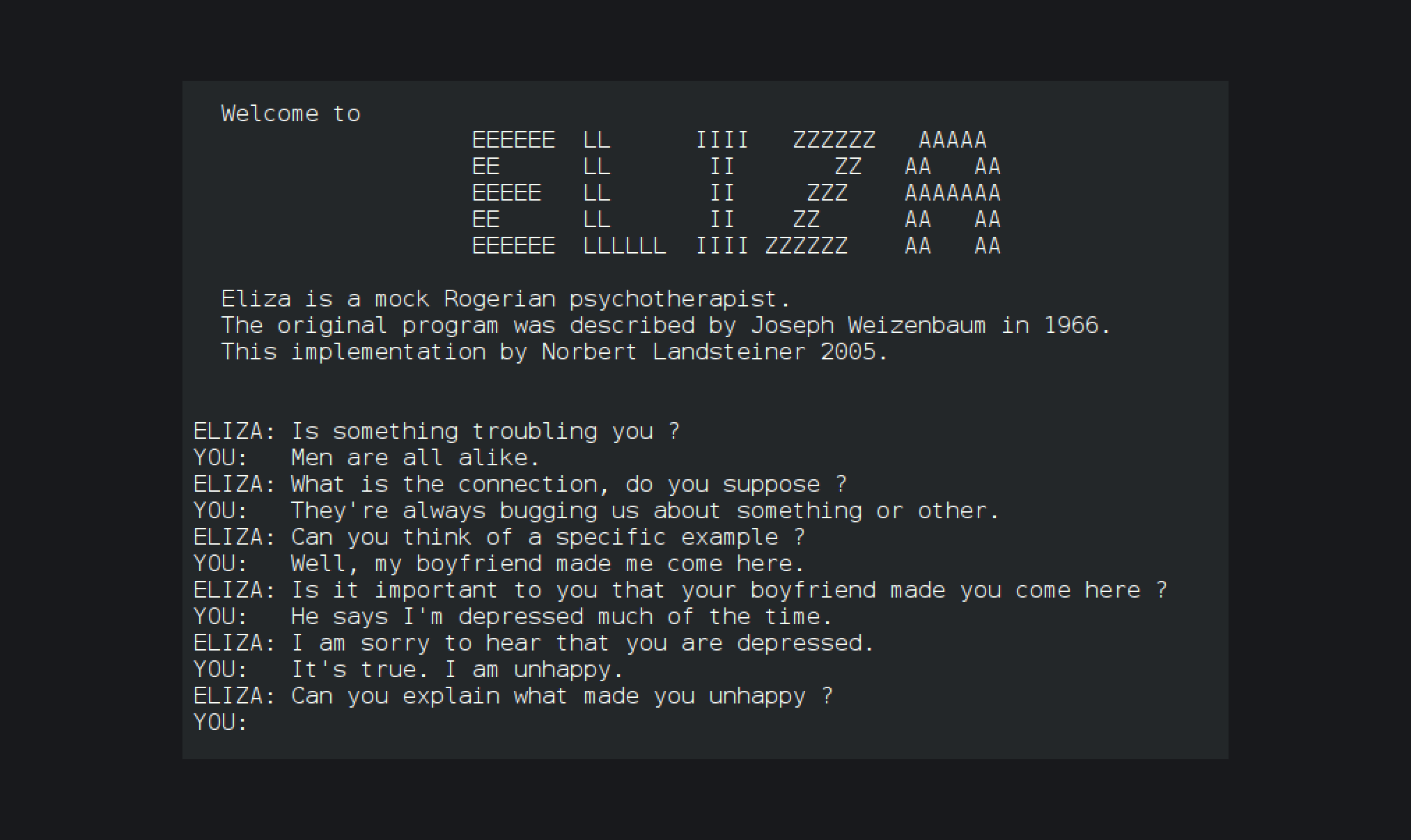
Inspired by ELIZA, in 1995, Richar Wallace composed ALICE ⎯ which was another significant milestone in interacting with computers with natural language.
ALICE was created to be a friendly entity on the internet that sought to be a friend you can talk to. It was one of the strongest programs of its kind and won the
Loebner Prize, awarded to accomplished humanoids. ALICE, however, was unable to pass the Turing test, as even the casual user will often expose its mechanistic aspects in short conversations.
It is necessary to mention ALICE as it served 2 key functions, besides being a big push for chatbots to go mainstream -
- It inspired Adam Spiegel (or Spike Jonze) to serve as the foundations for his 2013 Academy-award winning film - Her, that went on to become a benchmark for how far we can push these algorithmic entities to be closer to human beings.
- The program uses an XML Schema called AIML (Artificial Intelligence Markup Language) for specifying the heuristic conversation rules ⎯ and introduces the concept of using structured data to converse with a machine.
In the period between ELIZA’s rise and ALICE’s coming to life, there was another group of researchers at XEROX PARC working on something they christened GUS ⎯ or Genial Understander System.
The idea behind GUS was pretty straightforward - get things done on your computer by just talking naturally with a chatbot. GUS’s starting point was a travel agent with whom you could converse to book a flight to San Diego at the time of your choosing.
It is pretty simple use case to start with, but it was an important milestone as systems as they had been defined before worked strictly with specifically structured data, while natural language based systems are supposed to be more fluid and generalised. GUS was a big step in implementing interoperability of systems based on structured data to systems based on natural language.

Umpteen thinkers and computer scientists in the latter half of 1900s were tinkering with ideas on how can computers augment human intellect. In his seminal 1962 essay ⎯ Augmenting Human Intellect : A Conceptual Framework, Douglas Engelbart mentions enhancing the capacity of comprehension to grasp complex problems and offer speedier resolutions as the end goal of where we want computers to go.
Engelbart was not alone in this thinking, and inspired other scientists like Alan Kay to study how computers could amplify and perhaps help articulate the human imagination. While these early manifestations of tools unlocked pioneering ideas on the relationship between humans and machines, they were largely conceptual. Engelbart and Kay’s work hinted at a future of creative tools built to enhance the human mind’s creativity and intellect, but the translation of these ideas to tangible artefacts came along much later, in different forms.
In a 1945 essay titled As we may think, Vannevar Bush coined the term "memex". Bush's memex was based on what was thought, at the time, to be advanced technology of the future: ultra high resolution microfilm reels, coupled to multiple screen viewers and cameras, by electromechanical controls. The memex, in essence, reflects a library of collective knowledge stored in a piece of machinery described in his essay as "a piece of furniture".
The essay predicted (to some extent) umpteen different kinds of technology invented after its publication, including hypertext, personal computers, the Internet, the World Wide Web, speech recognition, and online encyclopaedias such as Wikipedia ⎯ "Wholly new forms of encyclopaedias will appear, ready-made with a mesh of associative trails running through them, ready to be dropped into the memex and there amplified." Bush envisioned the ability to retrieve several articles or pictures on one screen, with the possibility of writing comments that could be stored and recalled together. He believed people would create links between related articles, thus mapping the thought process and path of each user and saving it for others to experience. Wikipedia is one example of how this vision has, in part, been realised, allowing elements of an article to reference other related topics. A user's browser history maps the trails of possible paths of interaction, although this is typically available only to the user that created it.
Modern tools
In the early 2000s, we came across SmarterChild ⎯ an intelligent agent or “bot” created by ActiveBuddy that could do a whole lot of things.
The concept for conversational instant messaging bots came from the founder's vision to add natural language comprehension functionality to the increasingly popular AOL instant messaging application. The original implementation took shape as a demo that Timothy Kay (founder of ActiveBuddy) programmed in Perl in his Los Altos garage to connect a single buddy ⎯ "ActiveBuddy", to look up stock symbols, and later allow AOL users to play Colossal Cave Adventure, a famous word-based adventure game, and MIT's Boris Katz Start Question Answering System but quickly grew to include a wide range of database applications the company called 'knowledge domains' including instant access to news, weather, stock information, movie times, yellow pages listings, and detailed sports data, as well as a variety of tools (a personal assistant, calculator, translator, etc.)
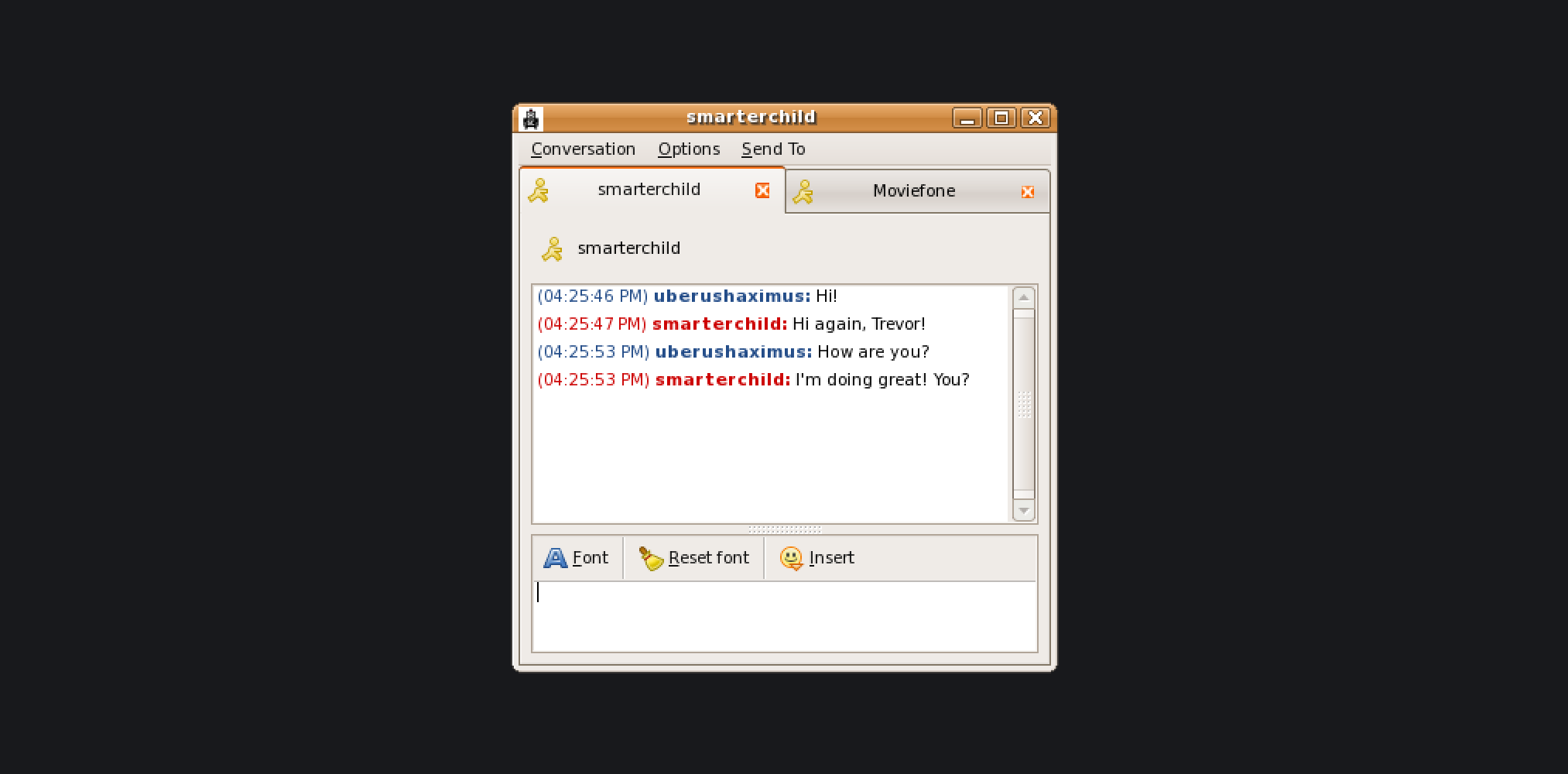
Services like SmarterChild and Wolfram Alpha (and it’s elder sibling ⎯ Wolfram Mathematica) were essentially precursors to modern day Siri and Google Assistant. In fact, Shawn Carolan of Menlo Ventures, an investor in Siri , once said, "…when I first encountered Siri, SmarterChild already had ten million users and was getting a billion messages a day… The market was speaking."
Half a decade after Siri’s initial release, Facebook (now Meta) released M, it’s own personal assistant, and a whole new ecosystem to build bots on Facebook Messenger. While the fundamentals remained the same, companies kept building tools to make it easier to extract intents from statements. Early tools like Google’s API.ai (later christened Dialogflow) let users program custom events and actions tied to inputs, but the key issue in machine learning systems remained, having access to enough data to convince the machine that “I want to hear the Eagles” still meant you want to listen to Hotel California and not this.
The advent of Large Language Models does alleviate the resource conflict we used to face earlier while building systems that can extract intents from a wide array of possible input statements. But in the absence of an ability to interface with deterministic systems that are built to understand and work with structured data, we still have a chasm to cross.
In spite of the technology industry’s investments in recreating human intelligence, the computer’s capacity to be fulfill a task is still entirely dependent on the operator’s ability to program that prescriptive creativity step-by-step into a machine. As Tony McCaffrey of There Will Always Be Limits to How Creative a Computer Can Be states, “The fastest modern supercomputer couldn’t list or explore all the features of an object/thing even if it had started working on the problem way back in the 1950s. When considering the Obscure Features Hypothesis for Innovation, which states that every innovative solution is built upon at least one new or commonly overlooked feature of a problem, you can see how AI may never advance enough to take the jobs of Chief Innovation Officers.”
While there are situations in which computers are able to figure out the steps needed to get from state A to a different state B, it is still within the limitations of human-mandated decomposition. This means that the actions we take with computers are steps that we have already broken down in our head in order to achieve an end result.
Doneth
We looked around to find use cases for a possible proof of concept of using LLMs as a form of general purpose classifier to extract intents from statements with minimal pre-training. We looked for what we do often that can be easily automated, accelerated, or enhanced with GPT-3. We initially gunned to build an intelligent omnibox, a fusion of Siri and Spotlight, powered by GPT-3. We discarded the idea because the omnibox would not be very useful without an array of key integrations.
For eg - If I write Schedule a meeting with Alex Ohanian tomorrow at 6:30pm PT in my Omnibox, I would expect the Omnibox to have Calendar and Zoom integrations ready to fire and set things up for me. If that were possible, we would have possibly been building the next Zapier, powered by GPT-3. But this is a tall ask, considering building Integrations is a tall task. We fell back to something far more prevalent and obvious.
A to-do app.
Obviously, a to-do app is as simple as it gets to building a project. In fact, it is the Hello World for anyone getting started with building for the web, iOS, or Android. We wanted to transform this simple to-do app into something far more powerful.
Why a to-do app?
To-do apps are one of the highest used apps/services across the world. Notion was initially built to be a to-do app before the creators expanded its feature set. You have the Big 3 - Google, Microsoft, and Apple, all running to build the next best to-do app. There are independent companies ⎯ Evernote, and Todoist : million-dollar businesses that try and help users get things done.
The question is, do they actually help you get things actually "done" though? Or just add an additional cognitive load by reminding the user that they still have a load of things to do.
With Doneth, we are trying to change that. We have started small, nothing too big or out of the world yet. But we want to build meaningful interactions for the most common and obvious tasks, right inside your to-do list. We want the user to not - open their to-do list → exit and open the relevant app → do something / check for a movie / find a recipe → repeat.
To break this cycle, we are bringing intent-driven actions right inside your to-do list.
With Doneth, we have identified some of the most common tasks that users list on their to-do list and have added microapps right inside Doneth so that they can check what they need to do without having to leave their list and go somewhere else. The idea is simple enough - you add a task, and Doneth figures out which microapp would you potentially need to fulfill the said task. You click on the microapp button that pops up right below your task and the window to fulfill your task comes up. Now, there is a huge ocean of things we can do here. Powered by GPT-3, Doneth is pretty accurate as to figure out the intent and extract the necessary entities from a natural language statement. The caveat? We have not been able to build a whole arsenal of microapps that we would have loved to integrate. We have a handful of them ready to go, and we would cover more on them, and how they work in due course of this article.
Here’s a preview of how Doneth works 👇
The user opens the webpage (the current implementation of Doneth is just on the Web) and encounters a text field, an add button, and a list of tasks. No frills or features to sidetrack you from what you came on to do ⎯ to add your task, and at some point, get it done.
Once you add your task, it takes some time for your task to get added to the Task list (reason - GPT-3 APIs are excruciatingly slow), but when it does, it has a small button that let's you do, or rather, makes it easier to do, what the user has mentioned that they need to get done.
Now, since this project was built with the intention to showcase and experiment with GPT-3, the user might not find every single feature they would associate with a to-do app because of course, our priorities were slightly different. We prioritised adding a bunch of microapps over priority labels, but we promise it's all for the greater good. If Doneth does go to market someday, it would sure sport the regular features that grace other to-do apps.
Micro-apps
With all focus on these smaller integrations, what did we end up integrating to Doneth in the first place?
v0.2.0, as of the time of writing this report, Doneth has 7 live text-based integrations -
- Find a movie (or TV Series) to watch
- Find something to eat (shows you a recipe)
- Write an essay (helps you expand and write on a topic)
- Summarize (helps you summarize something)
- Open a Map or help you call a cab
- Play Music
- Find/generate Study Notes
Key point to note is that many of these integrations in turn, are also powered by GPT-3.
But before we dive into what these integrations do and how they do it, we would take a look at GPT-3, the white paper behind it, and how the API comes together in creating Doneth.
GPT-3
tl;dr
GPT-3 is OpenAI's latest language model. It incrementally builds on model architectures designed in previous research studies, but its key advance is that it's extremely good at "few-shot" learning. There is a lot it can do, but one of the biggest pain points is in "priming," or seeding, the model with some inputs such that the model can intelligently create new outputs. Many people have ideas for GPT-3 but struggle to make them work, since priming is a new paradigm of machine learning.
Not tl;dr
Recent years have featured a trend towards pre-trained language representations in NLP systems, applied in increasingly flexible and task-agnostic ways for downstream transfer. First, single-layer representations were learned using word vectors and fed to task-specific architectures, then RNNs with multiple layers of representations and contextual state were used to form stronger representations (though still applied to task-specific architectures), and more recently pre-trained recurrent or transformer language models have been directly fine-tuned, entirely removing the need for task-specific architectures.
This last paradigm has led to substantial progress on numerous challenging NLP tasks - such as reading comprehension, answering questions, textual entailment, and many others, and has continued to advance based on new architectures and algorithms. However, a major limitation to this approach is that while the architecture is task-agnostic, there is still a need for task-specific datasets and task-specific fine-tuning: to achieve strong performance on a desired task typically requires fine-tuning on a dataset of thousands to hundreds of thousands of examples specific to that task. Removing this limitation would be desirable, for several reasons -
- First, from a practical perspective, the need for a large dataset of labeled examples for every new task limits the applicability of language models. There exists an extremely wide range of possible useful language tasks, encompassing anything from correcting grammar to generating examples of an abstract concept, to critiquing a short story. For many of these tasks, it is difficult to collect a large supervised training dataset, especially when the process must be repeated for every new task.
- Second, the potential to exploit spurious correlations in training data fundamentally grows with the expressiveness of the model and the narrowness of the training distribution. This can create problems for the pre-training plus fine-tuning paradigm, where models are designed to be large to absorb information during pre-training but are then fine-tuned on very narrow task distributions.
- Third, humans do not require large supervised datasets to learn most language tasks – a brief directive in natural language (e.g. “Please tell me if this sentence describes something happy or something sad”) or at most a tiny number of demonstrations (e.g. “here are two examples of people acting brave; please give a third example of bravery”) is often sufficient.
One of the ways to solve this issue might be through "meta-learning", which in the context of language models means the model develops a broad set of skills and pattern recognition abilities at training time and then uses those abilities at inference time to rapidly adapt to or recognize the desired task.
The original GPT-3 white paper, explores some of these methods and decides to go ahead with another trend in the NLPverse - increasing parameters to a transformer model.
To quote the authors -
In the paper, the hypothesis is tested by training a 175 billion parameter autoregressive language model, and measuring its in-context learning abilities. Specifically, the authors evaluated GPT-3 on over two dozen NLP datasets, as well as several novel tasks designed to test rapid adaptation to tasks unlikely to be directly contained in the training set.
GPT-3 was evaluated under 3 conditions -
- “few-shot learning”, or in-context learning where the authors allowed as many demonstrations as will fit into the model’s context window (typically 10 to 100),
- “one-shot learning”, where only one demonstration is allowed, and
- “zero-shot” learning, where no demonstrations are allowed and only an instruction in natural language is given to the model.
Results
Broadly, on NLP tasks GPT-3 achieves promising results in the zero-shot and one-shot settings, and in the few-shot setting is sometimes competitive with or even occasionally surpasses state-of-the-art (despite state-of-the-art being held by fine-tuned models). For example, GPT-3 achieves 81.5 F1 on CoQA in the zero-shot setting, 84.0 F1 on CoQA in the one-shot setting, and 85.0 F1 in the few-shot setting. Similarly, GPT-3 achieves 64.3% accuracy on TriviaQA in the zero-shot setting, 68.0% in the one-shot setting, and 71.2% in the few-shot setting, the last of which is state-of-the-art relative to fine-tuned models operating in the same closed-book setting.
To know more about GPT-3 and how the authors achieved these results, here is the original paper - https://arxiv.org/pdf/2005.14165.pdf
OpenAI API

GPT-3 the model and its details were not released to the general audience.
But on June 11, 2020 - OpenAI exposed the model in the form of a restricted API for beta users.
Given any text prompt, the API will return a text completion, attempting to match the pattern the user gives it. We can “program” it by showing it just a few examples of what you’d like it to do (few-shot learning); its success generally varies depending on how complex the task is. The API also allows us to hone performance on specific tasks by training on a dataset (small or large) of examples we provide, or by learning from human feedback provided by users or labelers.
Microsoft is one of the biggest names to license GPT-3 to improve its low-code offering - the Power FX programming language available in MS Excel, to better detect syntax errors, and parametric anomalies, and fix them on the fly for the user (a GPT-3 powered autocorrect is a suitable analogy).
Recently, another of GitHub's bigger acquisitions - GitHub released the
Copilot, a code-completion extension for VS Code similar to what Smart Replies does for Gmail - augments the user by predicting what the next snippet of code should be.
How does it work?
Let's take a look at what the API Request looks like -
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"prompt": "$PROMPT_TEXT",
"temperature": 0.5,
"max_tokens": 100,
"top_p": 1,
"frequency_penalty": 0.2,
"presence_penalty": 0,
"stop": ["\n"]
}'
Prompt
The prompt is a selection of curated Inputs and Outputs that we feed into GPT-3 to ensure that it gives us an output in accordance with a pre-defined pattern. We mentioned few-shot learning earlier, and with the prompt that is what we try to do, instead of simply relying on GPT-3 to give a random output.
A prompt is far smaller than any traditional dataset. But the way GPT-3 has been trained for multiple use cases, a few-shot learning paradigm makes it easier for us to re-orient the model to give outputs in a pre-defined pattern.
Temperature
One of the most important settings to control the output of the GPT-3 engine is the temperature. This setting controls the randomness of the generated text. A value of 0 makes the engine deterministic, which means that it will always generate the same output for a given input text. A value of 1 makes the engine take the most risks and use a lot of creativity.
Max Tokens
Denotes the number of tokens that would be used in the output sequence text.
The default setting for response length is 64, which means that GPT-3 will add 64 tokens to the text, with a token being defined as a word or a punctuation mark.
Top P
The “Top P” parameter also has some control over the randomness of the response.
Frequency and Presence Penalty
Frequency penalty works by lowering the chances of a word being selected again the more times that word has already been used. The presence penalty does not consider how frequently a word has been used, but just if the word exists in the text.
The difference between these two options is subtle, but you can think of the Frequency Penalty as a way to prevent word repetitions, and the Presence Penalty as a way to prevent topic repetitions.
Stop sequence
The “Stop Sequences” option allows us to define one or more sequences that when generated forces GPT-3 to stop.
Language Models
The OpenAI API comes with a few language models that we can use. In the API request above, they are called engines -
v1/engines/davinci - davinci is one of the predefined language models. There are a few more -
Davinci
Davinci is the most capable engine and can perform any task the other models can perform often with less instruction. For applications requiring a lot of understanding of the content, like summarization for a specific audience and creative content generation, Davinci is going to produce the best results. These increased capabilities require more computing resources, so Davinci costs more per API call and is not as fast as the other engines.
Another area where Davinci shines is in understanding the intent of the text. Davinci is quite good at solving many kinds of logic problems and explaining the motives of the characters. Davinci has been able to solve some of the most challenging AI problems involving cause and effect.
Good at: Complex intent, cause, and effect, summarization for audience.
Curie
Curie is extremely powerful, yet very fast. While Davinci is stronger when it comes to analyzing complicated text, Curie is quite capable for many nuanced tasks like sentiment classification, and summarization. Curie is also quite good at answering questions and performing Q&A and as a general service chatbot.
Good at: Language translation, complex classification, text sentiment, summarization.
Babbage
Babbage can perform straightforward tasks like simple classification. It’s also quite capable when it comes to Semantic Search ranking how well documents match up with search queries.
Good at: Moderate classification, semantic search classification.
Ada
Ada is usually the fastest model and can perform tasks like parsing text, address correction and certain kinds of classification tasks that don’t require too much nuance. Ada’s performance can often be improved by providing more context.
Good at: Parsing text, simple classification, address correction, keywords.
Intent extraction with GPT-3
In the ideal scenario, a paradigm where Large Language Models can switch to a deterministic mode to send a response, we’d just pass the input statement and receive a structured response that we can work with further.

A few tries in, it became clear that GPT-3 was bad at adhering to a specific format. And even if the format has been repeated in the context prompt, there were a lot of instances of hallucination where the LLM is dreaming up its own schema, and adding key-value pairs that have not been defined.
Even the parameters of the JSON object that were added to the prompt were getting shuffled around or being re-worded. We cannot exactly listen for a field for intent when GPT-3 in its response, transforms it to intention.
One important piece that sets apart this approach from regular classification is that we wanted to also extract arguments from the statement, not just the intent. In a to-do app, you don’t have the affordances to ask the user repeatedly to input arguments, so the entire context needs to be extracted from the get-go.
For eg - Say I want a music player built right inside doneth. I have added a to-do : “Play Indian Ocean on loop at night”. Now from this statement, I want the intent of the user, let’s call it play-music and to the corresponding function that gets called for this intent, say function play_music(), I would also want to pass the band name as a parameter so that I can build a construct where the user clicks on the Play Music button, the program can automatically open Spotify with the artist’s page in front ⎯ ready to play their songs.
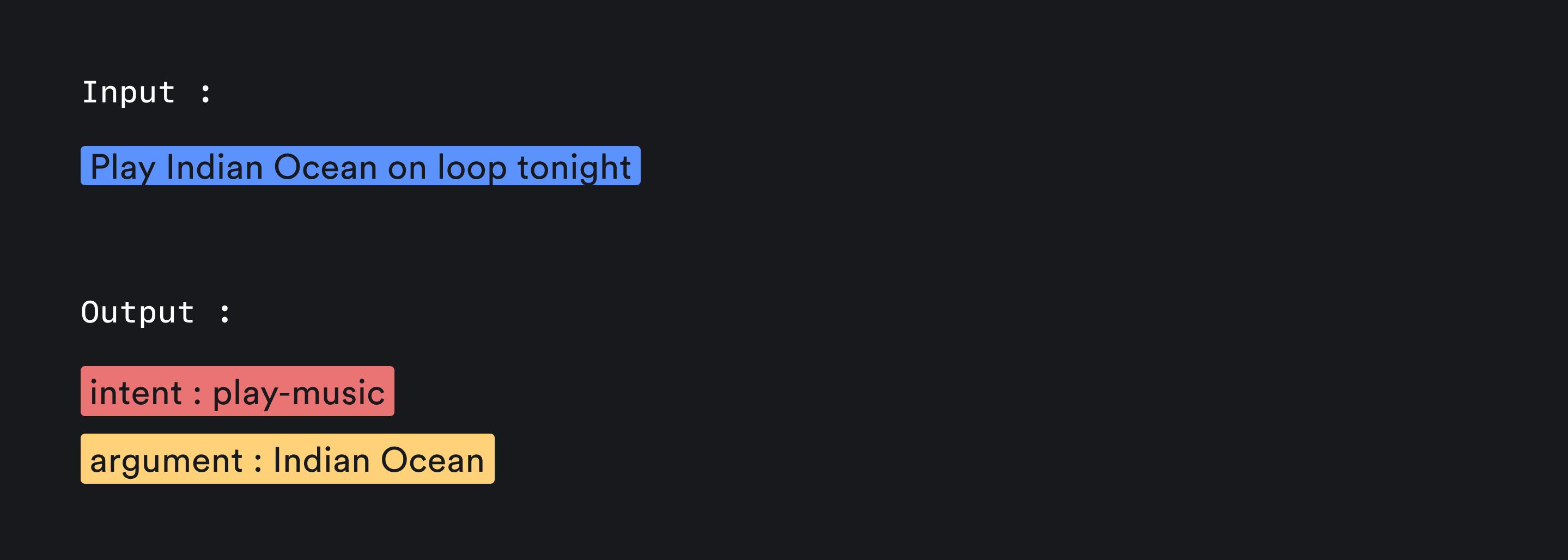
When you get both the intent and the argument(s), it affords a far easier picture for you to render dynamic interfaces on top of this ⎯ and this can be extended into far more complex scenarios, converting the LLM into essentially a search engine in latent space. You can also think of a scenario where you can use the intent and arguments to launch other LLMs, like Dall-E to achieve more.

The current state of LLMs being a black box can be solved to a certain extent by reducing a natural language input into its corresponding intent and arguments ⎯ . This leads to a more powerful pattern of rendering full-fledged micro-apps inside the context of a conversation.
Imagine wanting to play sudoku, and a sudoku game is rendered for you on the fly, or a relevant part of your calendar becomes visible when you are trying to resolve a scheduling conflict conversationally.
As JSON output is not readily available, we developed a formatting technique that the LLM can follow while answering. And since this formatting is derived from a simple string manipulation concept using delimiters, GPT-3 did not have much trouble generating consistent, parseable outputs. This is the formatting scheme we arrived at 👇

Initially, when you’re writing a to-do, we send a prompt that allows us to parse any input text into a series of entities. The way we have structured the entities is that the first of the entity series denotes the intent, and the subsequent elements, reflect the multiple parameters that we can use while building integrations further down the line.
Example Prompt -
A: book-cab / to college / tomorrow
Q: Play a song from Cactus
A: play-song / cactus
where Q → Input prompt; A → Expected output
The actual prompt consists of quite a few more sample input-output sets.
Once we get the response, we run the split() function in Javascript and extract the intent and other parameter entities from the resultant array. Now we have ensured that we receive the data as a string, we can optimize the response to resemble a structured JSON from where we can simply extract the parameters, as they would surely increase the load as we move towards building more complex interactions.
We also envision Doneth to not just be a tool, but a platform. Accordingly, we have structured the code to make it extremely easy to plug in new interactions and micro-apps. We do not have complete developer documentation for it at the moment - but that is another task on the roadmap.
Final thoughts
Acknowledging that LLMs are not inherently creative/structured should not come as a surprise. However, it does point to the fact that we can leverage them to create far more nuanced, and personalized actions that help the human operator in achieving their tasks in a superior, and more efficient way. This facilitates a whole new arena of interfaces that render dynamic bits on the fly as and when the user needs them ⎯ this again caveats to the point of knowing which dynamic bit to render where.
When OpenAI released its code generation model - Codex, it raised expectations of the program knowing which bits of code to render, and in the future, it might lead to computers directly rendering a fresh component instead of just showing the code to render the said component.
Understanding the restrictions of technologies like Large Language Models gives us a better shot at making computers assume the role of a co-creator in human endeavors instead of just being a number-crunching machine. Not as an idea-generator, but more of an actualizer.
Imagine a paradigm a few years down the line when we have multiple companies releasing separate models that excel at one or two things. We might have a model that is exceptionally good with classifying intent and extracting arguments from an input statement, and we can leverage that to call other LLMs for the specified task ⎯ imagine calling Dall-E or Midjourney to generate images, some other model to generate music, you can render a micro-app to help tune your instrument, solve a crossword, etc. Routing these function calls to use an appropriate LLM would also enable us to chain contexts and pass information extracted by one model to another. In the case of image generation, this would allow us to stack prompts the same way we stack layers on Figma, and we would finally be able to fix hands.
The main essence distills down to having the autonomy to get an LLM to do what you want ⎯ instead of the LLM doing whatever they want and you having to tweak things around in other tools using the output.
Steve Jobs once explained during an interview in Memory & Imagination: New Pathways to the Library of Congress, “That’s what a computer is to me… it’s the most remarkable tool that we’ve ever come up with, and it’s the equivalent of a bicycle for our minds.”

This framing steers our attention towards reconfiguring our goal of building software systems intelligent enough to figure out the steps needed to produce a desired outcome in service of the operator’s broader vision. As Shan Carter and Michael Nielsen explain succinctly in
Using Artificial Intelligence to Augment Human Intelligence, “Intelligence Augmentation (IA), is all about empowering humans with tools that make them more capable and more intelligent, while Artificial Intelligence (AI) has been about removing humans fully from the loop.”
Framing our approach to building software in a way where LLMs should give you more control instead of remaining a black box unlocks a lot of different pathways in how we craft interfaces.
Doneth for a spin right now because GPT-3 and its associated APIs have since been sunset ⎯ and I have not refactored the codebase to use GPT-3.5 or above yet! That’s my to-do for 2024.